Документация системы МETA
Система «МЕТА» предназначена для комплексного подхода к автоматизации больших систем высокого класса и уровня сложности за счет встроенных механизмов саморегуляции.
Введение
Все понятия (МЕТА, блоки, цепочки, грозди, формы и пр.), которым посвящен этот документ, созданы в процессе автоматизации крупнейших проектов. Подробнее об этом вы можете прочитать в книге "Роботы работают".
Подходы и решения, описанные в этом документе, не претендуют быть единственно верными для построения больших информационных систем, но являются отражением накопленного опыта и результатом многолетнего труда.
Все разделы обязательны к прочтению, так как они взаимосвязаны между собой и зачастую одно вытекает из другого.
Этот документ предназначен для специалистов, занимающихся разработкой, модификацией и внедрением прикладных решений в области построения больших информационных систем.
Мы всегда готовы ответить на дополнительные вопросы, если они возникнут после прочтения этого документа.
Система МЕТА
Система МЕТА — совокупность методов и технических приемов, обеспечивающих глубокий комплексный подход к автоматизации систем любого класса и уровня сложности за счет встроенных механизмов саморегуляции.
Возможности системы
Система МЕТА позволяет повышать точность бизнес-аналитики и прогнозов, сокращает время работы с данными и в несколько раз ускоряет процесс принятия решений, так как все прогностические параметры видны и прозрачны.
Более того, видна вся история работы с данными: кто, когда и по какому поводу вносил изменения. Система оцифровывает бизнес-процесс постепенно, слой за слоем, сохраняя все предыдущие версии. В случае обнаружения ошибки всегда можно вернуться к первоначальной версии — процесс не пострадает, а ошибка может быть исправлена в кратчайшие сроки, так как в случае ошибки все необходимые параметры видны. Таким образом, система обеспечивает устойчивость себе и тем бизнес-процессам с которыми работает.
Система МЕТА снижает и минимизирует вероятность человеческих оплошностей, делает процессы прозрачными и управляемыми, обеспечивает полный контроль происходящего по тому или иному направлению бизнес-процесса. Результаты принятых решений можно отслеживать в реальном времени.
При этом сама творческая составляющая процесса принятия решений по-прежнему полностью принадлежит руководителю. Управленческие и судьбоносные решения будет принимать руководитель, система лишь даст нужные для принятия решения данные и сделает это с высокой скоростью и точностью, с той степенью детализации, которая нужна для каждого управленческого уровня.
Базовая структура системы МЕТА и общие понятия
Для того, чтобы понять, как устроена МЕТА на табличном уровне, вспомним, что такое классическая реляционная модель данных и база данных на ее основе.
Спроектируем, для примера, сильно упрощенную базу данных туристов, в которой будет содержаться только две сущности — человек и страна (для определение гражданства). Тогда модель наших даных и таблицы для хранения данных будут выглядеть следующим образом:
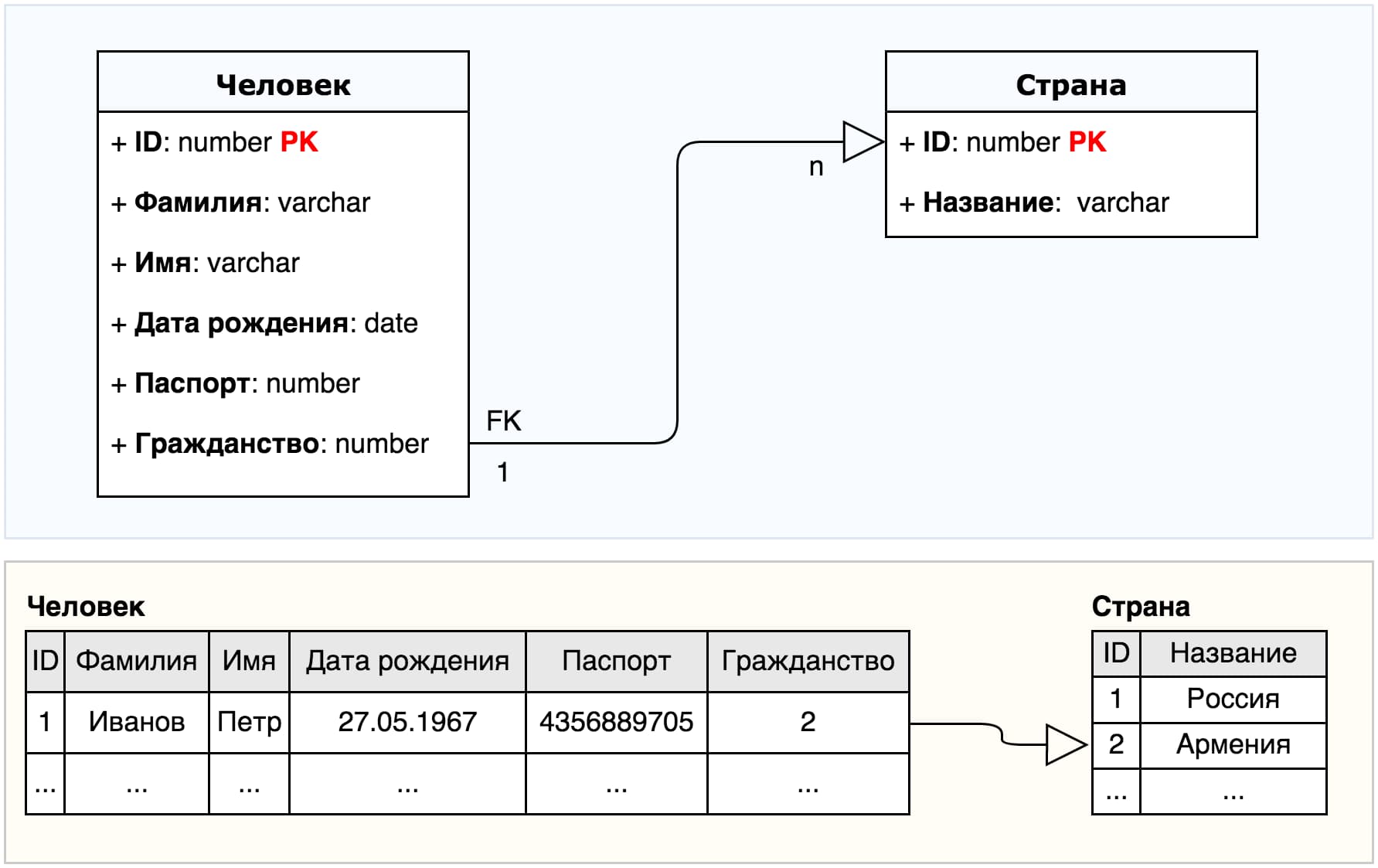
Под каждую сущность выделяется отдельная двумерная таблица, столбцы которой - это атрибуты (характеристики) сущности, а строки таблицы - это экземпляры сущности. Каждый экзмпляр сущности обязан иметь уникальный идентификатор (первичный ключ, PK - primary key). Связи между двумя сущностями осуществляются через указание внешних ссылок на идентификаторы связанных сущностей (внешний ключ, FK - foreign key).
Например, в таблице "Человек" для туриста с идентификатором 1 в атрибуте "Гражданство" прописан инденфикатор страны из таблицы "Страна".
Теперь рассмотрим, как та же самая модель данных разложена в таблицах системы МЕТА:
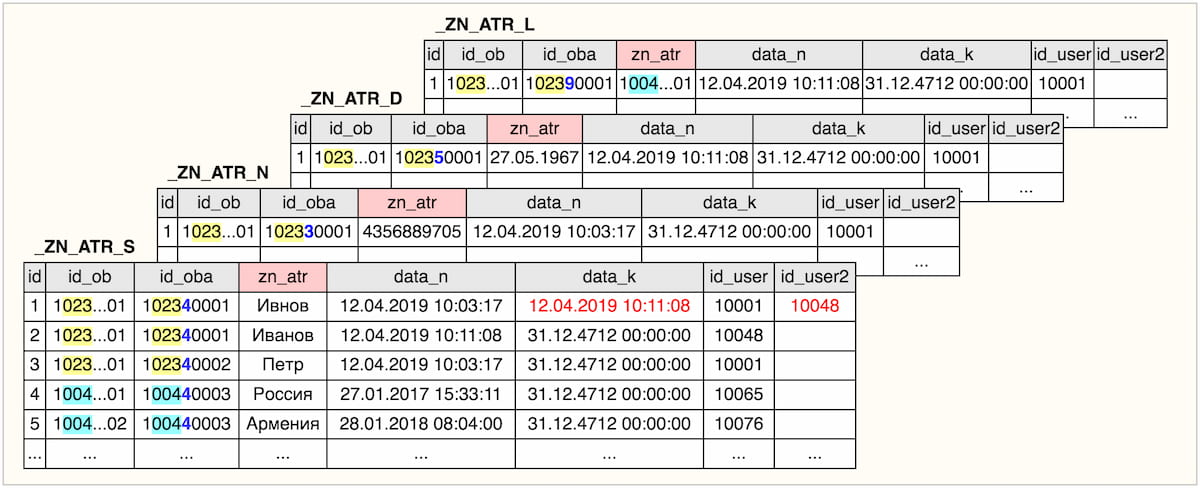
Независимо от того, сколько сущностей будет содержать база данных, МЕТА состоит всегда из 4 таблиц, структура которых идентична:
- таблица для хранения строковых значений атрибутов объектов <some_prefix>_zn_atr_s
- таблица для хранения числовых значений атрибутов объектов <some_prefix>_zn_atr_n
- таблица для хранения дат и времени в значениях атрибутов объектов <some_prefix>_zn_atr_d
- таблица для хранения ссылочных значений атрибутов (внешних ключей) объектов <some_prefix>_zn_atr_l
Каждой сущности присваивается номер от 0 до 999. В системе МЕТА сущностью мы будем называть тип.
В рассматриваемом примере Человек — это тип 23, а Страна — тип 4.
Каждый экземпляр сущности в системе МЕТА мы будем называть объектом.
В рассматриваемом примере Иванов Петр со всеми характеристиками — это объект типа 23, а Армения и Россия — объекты типа 4.
Каждому объекту МЕТА генерирует уникальный идентификатор (ID). Идентификатор может состоять из 12 или 18 (для блочных объектов) цифр (см. Блоки).
Идентификатор генерируется по алгоритму и включает такую информацию об объекте как: номер типа, номер блока (для блочных объектов), номер хоста (для блочных объектов), номер цепочки (для блочных объектов) и произвольный набор цифр:

Каждому атрибуту типа присваивается номер по порядку, в номере учитывается номер типа (сущности) и тип атрибута (строка/число/дата/ссылка).
В рассматриваемом примере Фамилия — это строковый атрибут с номером 1023400001, Имя — строковый атрибут с номером 1023400002, Название страны - строковый атрибут с номером 100440003, Номер паспорта — числовой атрибут с номером 102330001 и т.д.
Каждое значение атрибута типа (каждая строка любой таблицы системы МЕТА) имеет дополнительную важную информацию о себе:
-
дата и время вставки записи в таблицу —
data_n -
идентификатор пользователя, который вставил запись в таблицу —
id_user -
дата и время удаления записи из таблицы —
data_k. По-умолчанию для актуальной записи это дата будет равна31.12.4712 00:00:00(далекое будущее) -
идентификатор пользователя, который удалил запись из таблицы —
id_user2
data_k.Объект извлекается из системы МЕТА по состоянию на какой-то момент времени (по-умолчанию — на текущий момент), т.е. в условии SQL-запроса всегда есть проверка значения поля
data_k. Таким образом мы всегда можем узнать, каким объект был , как менялся и каким он стал (на текущий момент). Подробнее см. Физическая дата.
Префикс у таблиц системы МЕТА (<some_prefix>) включает название модуля и номер блока, если блок есть и он не 0-ой (см. Блоки). Оба понятия (модуль и блок) служат для физического разделения хранимых данных. При этом сами данные могут представлять логически связанную структуру. Например, все объекты типов, относящихся к классу справочников, могут содержаться в таблицах с префиксом spr_, а данные, относящиеся к туристам, в таблицах с префиксом trs_. Но только вместе все таблицы этих модулей будут представлять единую целостную базу данных.
За все операции с данными из программного кода отвечает библиотека lib_meta.jar (см. Библиотека lib_meta.jar). С ее помощью можно создать объект определенного типа, отредактировать его, сделать выборку объектов по условиям и др. При этом разработчику кода не придется строить SQL-запросы, и он может не знать, к каким таблицам он обращается и в каких базах данных они находятся.
Физическая дата datafis
Физической датой (сокр. физдатой) будем называть любую точку на линии времени (как правило, в прошлом), на момент наступления которой запрашивается состояние объекта или набора объектов системы МЕТА. Под состоянием объекта здесь подразумевается набор значений его атрибутов.
Например, 12.04.2019 в 10:03:17 в системе МЕТА был создан турист Ивнов Петр 27.05.1967 года рождения. Затем пользователь заметил опечатку в фамилии туриста и исправил ее в 10:11:08, добавив также номер паспорта и гражданство. После чего, в 12.04.2019 13:00:00 турист был вовсе удален из базы.
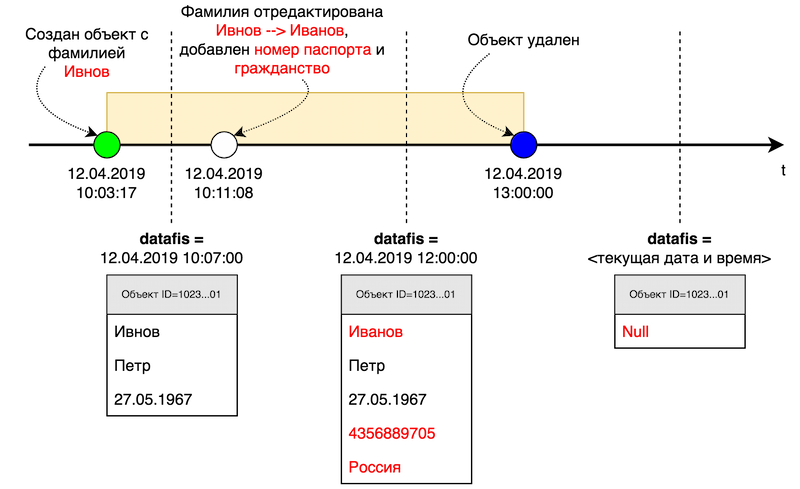
Если запросить у системы МЕТА объект этого туриста на физдату равную 12.04.2019 10:07:00, то мы получим туриста с опечаткой в фамилии, без номера паспорта и без гражданства.
Если запросить у системы МЕТА объект этого туриста на физдату равную 12.04.2019 12:00:00, то мы получим туриста с корректной фамилией и полным набором данных.
Если запросить у системы МЕТА объект этого туриста на текущий момент времени, то МЕТА вернет null (пусто), т.к. объект хоть и был ранее, но на текущую физдату его уже нет.
С точки зрения анатомии SQL-запроса к системе МЕТА, запрос на физдату — это условие datafis между датами data_n и data_k, применяемое ко всем строкам таблиц системы МЕТА с id_ob равному ID запрашиваемого объекта.
Блоки
1. Определение
Блоками будем называть хранилища данных, которые содержат часть данных определенного типа (здесь и далее в этом разделе под типом подразумевается тип системы МЕТА, т.е. сущность). Каждая часть данных выделена из общего объема данных по логическому признаку таким образом, чтобы для любого объекта всегда можно было однозначно определить его хранилище, т.е. блок.
Путем разбиения данных на блоки достигается не только логическое, но в первую очередь физическое распределение объемов хранимых данных, что в конечном счете положительно влияет на производительность системы в целом.
К хранению данных по блокам следует прибегать в случае, если количество объектов определенного типа постоянно увеличивается.
Как показывает практика, в большинстве случае логическим признаком разделения на блоки выступает какая-либо временная отсечка, которая фигурирует в объекте в качестве значения атрибута и которая даст относительно равномерное распределение данных по блокам.
Примеры.
-
система содержит и обрабатывает данные об учениках, число которых постоянно растет. В данном случае временной отсечкой будет выбрана дата рождения ученика, а точнее — год рождения, и все ученики будут распределены по блокам согласно их году рождения. Таким образом, каждый год рождения — это блок (например, 198001 - 1980 год рождения), т.е. структура блочности — по годам;
-
туроператор ежедневно продает сотни турпутевок. В данном случае временной отсечкой будет выбрана дата начала тура, а точнее — год и месяц начала поездки. Таким образом, блоками здесь будут каждый месяц года (например, 200801 - август 2020 года), т.е. структура блочности — по месяцам.
В рамках одного проекта, "блочных" типов может быть несколько. Также в одном проекте может быть не только несколько блочных типов, но и несколько блочных структур: блоки по месяцам, блоки по годам и др. варианты блочности.
Блочная структура может быть как общей для разных типов, так и отдельной под каждый тип (или набор типов). Например, в туроператоре есть блочные базы с заявками (и сопутствующими данными для них), так и отдельные блочные базы с чеками. Структура блочности у них одинаковая (по месяцам), а физически базы — разные. То есть несколько разных типов могут логически объединяться в одну блочную структуру, но при этом физически могут находиться в разных блочных структурах.
2. Подготовка к созданию блочного типа
Для того, чтобы сделать тип блочным, необходимо обратиться к администратору системы и сообщить о том, что один или несколько типов системы МЕТА планируется сделать блочными. Администратор подготовит хранилище под блочные типы и включит типы в список блочных ("пропишет плейсы").
3. Работа с блочными типами из кода
3.1. Идентификатор объекта блочного типа
Идентификатор объекта блочного тип состоит из 18 цифр:
В состав идентификатора блочного объекта с 5 по 8 цифры входит номер блока, а точнее, первые четыре цифры блока.
Если блочный объект находится в 0-м блоке, то номер блока в идентификаторе будет заполнен нулями.
Пример.
-
анализ объекта системы МЕТА с идентификатором
104200000811275509: объект блочного типа (18 цифр), принадлежит типу 42, находится в нулевом блоке; -
анализ объекта системы МЕТА с идентификатором
103719110112178230: объект блочного типа (18 цифр), принадлежит типу 37, находится в блоке191101
3.2. Объект блочного типа: создание, чтение, редактирование
Для создания объекта в блоке, используется соответствующая сигнатура функции Ob0.addOb:
public static String addOb(ResourceBundle mains, String connname, Obb ob, int id_block, boolean with_commit, int chain)
mains — объект с параметрами соединения с БД
connname — имя соединения с БД (имя коннекшна к БД), по-умолчанию Ob0.metaconnname
ob — сохраняемый объект
id_block — блок, в который следует сохранить объект. Если объект блочный, но сохраняется в 0-й блок, то передать конструкцию Util.s2i(Util.getMains(mains, "host")) % 100
with_commit — выполнить ли сразу commit в БД, по-умолчанию true
chain — номер цепочки (см. Цепочки). Если объект не цепочечного типа, то передать -1. Функция Ob0.addOb возвращает присвоенный объекту идентификатор.
Для редактирования объекта блочного типа применяется стандартная функция редактирования Ob0.edtOb. Функция автоматически определят местонахождение объекта (по идентификатору) и поэтому не требует передачи дополнительных параметров (подробнее о функциях и методах см. Библиотека lib_meta.jar).
Для чтения объекта блочного типа используется стандартная функция чтения объекта из базы Ob0.getOb. Функция автоматически определят местонахождение объекта (по идентификатору) и поэтому не требует передачи дополнительных параметров (подробнее о функциях и методах см. Библиотека lib_meta.jar).
3.3. Выборка объектов блочного типа
Для выборки объектов блочного типа используется функция Ob0.getSrcObs с сигнатурами, включающими параметр int[] blocks, в который передается массив блоков, в которых будет произведен поиск объектов (подробнее о функциях и методах см. Библиотека lib_meta.jar).
3.4. Вспомогательные функции для работы с блоками
Функции библиотеки lib_meta.jar:
public static int id2block(String id) // возвращает номер блока по идентификатору объекта
Функции библиотеки util.jar:
public static int getBlock(Date forDate) //возвращает номер блока по дате типа Date (структура блока - по месяцам)
public static int getMonthBlockByDate(String std) // возвращает номер блока по дате типа String (структура блока - по месяцам)
public static int[] getBlocksByRange(String std, String ftd) // возвращает набор блоков соответствующих диапазону дат (структура блока - по месяцам)
public static int date2yearBlock(String sDate) // возвращает номер блока по дате типа String (структура блока - по годам)
Цепочки
В чем физический смысл цепочек?
Понятие и использование цепочек вытекает из естественного процесса роста системы.
На репликацию данных между серверами уходит время, могут возникать ошибки репликации из-за одновременного редактирования одного и того же объекта на разных серверах/базах (конфликты репликации). Для частичного решения этой проблемы разные части приложения, редактирующие определенные типы, разносятся на разные сервера таким образом, чтобы каждый тип редактировался только на одной базе, а на остальных только читался.
Однако этих мер оказывается недостаточно для обеспечения надежности системы, т.к. в случае отказа какого-либо сервера, отказывает не только часть сервисов, но и возможность работы с частью типов. Для некоторых типов временные простои не очень критичны, а для некоторых нельзя допускать полного отказа в работе с объектами.
Поскольку нельзя допустить одновременного редактирования одних и тех же объектов на разных базах, но при этом необходимо реализовать балансировку в работе с объектами одного типа, появилось понятие цепочки. Список соответствий номера цепочки (от 0 до 99) и сервера задается в property-файле параметра vltl_resource для java-приложений и в конфигурационных файлах nginx для проксирования на томкаты.
Возможность полного распределения работы, в том числе на запись, позволяет не только балансировать нагрузку на базы и томкаты, но и в случае отказа какого-либо сервера позволяет сохранить работоспособность бОльшей части функционала работы с цепочечными объектами.
Пример.
Туристические заявки редактируются на 5 базах. В случае выхода из строя одной из баз сохраняется полноценная работа с 80% заявок, остальные 20% остаются без возможности редактирования и сохраняют свое состояние на момент отказа. Однако сразу после восстановления базы работа с оставшимися 20% заявок будет полностью восстановлена.
Понятие цепочки также связано с понятием грозди. Когда несколько типов цепочечных объектов логически провязаны друг с другом (например, тур и части тура, заказ и позиции заказа) и требуют одновременной работы, логично редактировать их на одной базе, поэтому номера цепочек у всех подобных провязанных объектов одинаковые. Объекты с одинаковым номером цепочки и провязанные друг с другом будем называть гроздью, а первый объект грозди — родителем грозди. Например, для грозди тур (тип 44) + части тура (тип 45) + туристы (тип 23) + листы бронирования (тип 211) + пр., родителем грозди будет тур, т.к. именно с создания этого объекта начинается вся связка.
Работа с цепочками из кода
При работе с цепочечными объектами из кода, требуется строго соблюдать ряд правил:
-
при создании нового объекта, провязанного с уже сущестующим цепочечным объектом, необходимо передавать соответствующую цепочку родителя
-
при создании роботов, обрабатывающих цепочечные объекты, необходимо всегда проверять, что цепочка объекта входит в список цепочек, обрабатываемых этим сервером
-
при формировании
http-ссылок в коде илиhttp-запросов из кода, которые читают данные из цепочечного объекта или как-то обрабатывают их, необходимо первым параметром вquery_stringпередаватьIDлюбого цепочечного объекта этой грозди, чтобы сработали механизмы проксирования и запрос ушел на сервер, обрабатывающий именно эту цепочку
Для создания объекта цепочечного типа, используется стандартная функция Ob0.addOb с соответствующей сигнатурой, включающей параметр chain (см. Библиотека lib_meta.jar):
public static String addOb(ResourceBundle mains, String connname, Obb ob, int id_block, boolean with_commit, int chain)
Если объект не цепочечного типа, то в параметр chain передается -1.
Если объект входит в гроздь, то он должен унаследовать номер цепочки от родителя грозди или от любого объекта, входящего в эту гроздь. Для получения номера цепочки из ID объекта используется функция:
public static int id2chain(String id) // возвращает номер цепочки из ID объекта
Если объект будет первым объектом (родителем) грозди, то номер цепочки для такого объекта можно сгенерировать в коде, например, конструкцией (int) (System.nanoTime() % 100L).
При написании роботов для обработки цепочечных объектов, необходимо проверять принадлежност объекта цепочкам текущего сервера, и не пропускать те объекты, которые не принадлежат списку допустимых цепочек:
public boolean isMyChain(int nChain) // проверяет принадлежность цепочки списку допустимых цепочек текущего сервера
Библиотека lib_meta.jar
Библиотека lib_meta предназначена для работы с базой данных системы МЕТА. Она включает все необходимы методы и функции для чтение и записи данных в систему МЕТА, функционал для поиска объектов по заданым параметрам и т.п. Все это устроено таким образом, что не требует от разработчика знаний специфики СУБД и умения строить SQL-запросы.
Объект системы МЕТА и объект класса appt.meta3.Obb
Любой объект системы МЕТА (экземпляр сущности) в java находит свое представление в универсальной структуре класса appt.meta3.Obb библиотеки lib_meta:
// appt.meta3.Obb
public class Obb {
public String id = null; // ID объекта
public int id_type; // номер типа объекта
public HashMap<String, ArrayList<String>> zn = null; // значения атрибутов
public String data_n = null; // дата создания объекта (дата создания первого значения атрибута объекта)
public String data_k = null; // дата "смерти" объекта
public int id_user; // пользователь, который создал объект (создал первое значение атрибута объекта)
...
}
Вернемся к картинке, на которой изображено хранение в таблицах системы МЕТА экземпляра сущности Человек:
Объект с экземпляром Иванов Петр в java-объекте Obb будет иметь следующее представление:
| Поля Obb | Значения полей | Комментарий |
|---|---|---|
|
String id |
1023…01 |
идентификатор объекта |
|
int id_type |
23 |
номер типа объекта |
|
HashMap<String, ArrayList<String>> zn |
[102340001, Иванов] |
значения атрибутов объекта в формате ключ (номер атрибута) ⇒ значение атрибута |
|
String data_n |
12.04.2019 10:11:08 |
дата создания объекта (дата создания первого значения атрибута) |
|
String data_k |
31.12.4712 00:00:00 |
дата удаления объекта |
|
int id_user |
10001 |
пользователь, создавший объект (первое значение атрибута) |
Таким образом, в структуру Obb можно "упаковать" любой экземпляр сущности системы МЕТА.
Создание объекта
Для того, чтобы создать объект определенного типа в системе МЕТА, необходимо создать экземпляр класса Obb, заполнить все поля (заполнить атрибуты — значениями), а затем сохранить объект в систему МЕТА с помощью функции Ob0.addOb:
Obb ob = new Obb(23); // тип будущего объекта - 23 (Человек)
ob.id_user = 10001; // идентификатор пользователя, создающего объект
// заполняем Hashtable zn со значениями атрибутов
ob.addAt(102340001,"Иванов"); // addAt - метод, наполняющий *zn*
ob.addAt(102340002,"Петр");
ob.addAt(102350001,"27.05.1967");
ob.addAt(102390001,"100400000001");
String id = Ob0.addOb(mains,ob); //сохраняем объект в БД
String в формате ДД.ММ.ГГГГ для дат или ДД.ММ.ГГГГ ЧЧ:МИН:СЕК для дат со временем. Правило действует и в обратную строну: все функции библиотеки возвращают даты как строку в формате ДД.ММ.ГГГГ или ДД.ММ.ГГГГ ЧЧ:МИН:СЕК.
Поля data_n и data_k заполнять не требуется: data_n принимает текущую дату и время в момент вставки записи в таблицу, а для data_k поле заполняется значением по-умолчанию 31.12.4712 00:00:00.
Метод addAt наполняет в объекте структуру zn значениями атрибутов (не в БД, а в памяти jvm):
public void addAt(int id_at, String zn_atr)
id_at — номер атрибута
zn_atr — значение атрибута
Функция Ob0.addOb возвращает идентификатор, присвоенный новому объекту:
public static String addOb(ResourceBundle mains, Obb ob) //функция сохраняет в БД новый объект
mains — объект с настроечными параметрами системы МЕТА (см. ResourceBundle)
ob — сохраняемый объект
Функция Ob0.addOb имеет также расширенную сигнатуру для сохранения объекта в определенный блок (см. Блоки) и/или цепочку (см. Цепочки):
public static String addOb(ResourceBundle mains, String connname, Obb ob, int id_block, boolean with_commit, int chain) // функция сохраняет в БД новый цепочечный объект блочного типа
mains — объект с настроечными параметрами системы МЕТА (см. ResourceBundle)
connname — имя соединения с БД (имя коннекшна к БД), по-умолчанию Ob0.metaconnname
ob — сохраняемый объект
id_block — номер блока, в который следует сохранить объект, если объект блочный. Если объект не блочного типа, то передать 0
with_commit — выполнить ли сразу commit в БД, по-умолчанию true
chain — номер цепочки (см. Цепочки). Если объект не цепочечного типа, то передать -1.
Чтение объекта по идентификатору
Для чтения объекта системы МЕТА по его идентификатору используется функция библиотеки Ob0.getOb с различными сигнатурами, которая возвращает объект класса Obb.
Рассмотрим два самых распространенных вариант Ob0.getOb:
public static Obb getOb(ResourceBundle mains, String connname, String id, String datafis) // функция извлекает из БД объект по идентификатору на физдату
mains — объект с настроечными параметрами системы МЕТА (см. ResourceBundle)
connname — имя соединения с БД (имя коннекшна к БД), по-умолчанию Ob0.metaconnname
id — идентификатор объекта
datafis — физдата (см. Физическая дата), на которую извлекается объект. Для извлечения объекта на текущий момент передать null
И более кратная запись функции, где по-умолчанию datafis = null:
public static Obb getOb(ResourceBundle mains, String id) // функция извлекает объект из БД по идентификатору на текущий момент времени
mains — объект с настроечными параметрами системы МЕТА (см. ResourceBundle)
id — идентификатор объекта
Ob0.getOb не имеет сигнатуры с параметром блока для чтения блочных объектов, т.к. функция "сама" определяет по идентификтору (cм. Идентификатор объекта блочного типа), в какой блок следует обратиться за объектом
Редактирование объекта
Для редактирования объекта системы МЕТА необходимо заполнить структуру zn новыми значениями атрибутов, а затем зафиксировать изменения в БД вызовом функции Ob0.edtOb:
public static String edtOb(ResourceBundle mains, Obb ob) // функция записывает в БД изменения в значениях атрибутов объекта
Obb ob = Ob0.getOb(mains, "102320010112345678"); // получение объекта типа 23 (Человек) по идентификатору
ob.id_user = 10001; // идентификатор пользователя, изменяющего значения атрибутов объекта
ob.addAt(102340001,"Петров"); // меняем фамилию
ob.addAt(102330001,"4356889705"); // добавляем номер паспорта
Ob0.edtOb(mains,ob); // фиксируем изменения в БД
При редактировании любого объекта неявно для разработчика в системе МЕТА устанавливается блокировка. Блокировка необходима для того, чтобы редактирование одного и того же объекта выстраивалось в очередь и выполнялось последовательно, поскольку операция редактирования может занимать продолжительное время, и отсутствие последовательного выполнения операций может привести объект к неконсистеному состоянию.
Механизм блокировок реализован через установку ключа в редисе. Если при редактировании возникает ошибка, то блокировка снимается с объекта сама через 3 минуты. В это время другие запросы на редактирование этого объекта будут "ждать".
Механизм блокировок при редактировании — это подготовка к реализации транзакций в системе МЕТА, за счет которых можно будет вернуть или измененное состояние объекта, или отменить все изменения.
Параметр mains класса ResourceBundl
Класс java.util.ResourceBundle предназначен для чтения текстовых файлов с расширением properties (файлы ресурсов), в которых информация организована по принципу ключ=значение.
java.util.ResourceBundle и о файлах *.properties можно почитать в открытых источниках. Почти все функции и методы библиотеки lib_meta обязательным параметром принимают объект класса java.util.ResourceBundle, в котором содержится информация, "прочтенная" из файла ресурсов с расширением properties. Этот файл будем называть основным файлом ресурсов. В основном файле ресурсов содержатся настройки системы, из которых "разворачивается" вся инфраструктура системы МЕТА.
Для каждого сервлета имя основного файла properties прописано в конфигурационном файле web.xml контейнера сервлетов tomcat в секции <init-param>, например:
...
<servlet>
<servlet-name>SearchServlet</servlet-name>
<servlet-class>msh.SearchServlet</servlet-class>
<init-param>
<param-name>main_resource</param-name> // название параметра, который должен содержать имя основного файла ресурсов
<param-value>sh_main</param-value> // значение параметра, которое соответствует имени основного файла ресурсов
</init-param>
</servlet>
...
Для java-классов (например, Robot) имя файла ресурсов (без расширения) передается в качестве одного из аргументов при запуске класса:
/usr/java/latest/bin/java -cp /w2/srv/tomcat2/lib/*:/w2/srv/tomcat2/lib:/w2/srv/tomcat2/webapps/sh/WEB-INF/classes:/w2/srv/tomcat2/webapps/sh/WEB-INF/lib/* msh.Robot sh_main 0 eventredis 520Как правило, все необходимые для работы приложения файлы ресурсов располагаются в каталоге tomcat/lib и имеют в названии файла префикс, совпадающий с именем соответствующего приложения tomcat:
-bash-4.2$ ls /w2/srv/tomcat/lib/ | grep "properties"
sh_1C.properties
sh_fld.properties
sh_gql.properties
sh_im.properties
sh_lng.properties
sh_main.properties // <-- основной файл ресурсов приложения sh
sh_networkmap.properties
shq_main.properties // <-- основной файл ресурсов приложения shq
shq_networkmap.properties
shq_rights.properties
sh_rights.properties
sh_sap.properties
sh_upload.properties
sp_main.properties // <-- основной файл ресурсов приложения sp
sp_networkmap.properties
sp_rights.properties
Основной файл ресурсов отличается от других файлов наличием постфикса main, например: bg_main.properties (основной файл ресурсов для приложения bg) или sh_main.properties (основной файл ресурсов для приложения sh).
За составление содержимого основного файла ресурсов отвечает администратор системы. Также администратором системы составляются и поддерживаются другие настроечные файлы ресурсов — vltl и networkmap.
В mains, vltl и networkmap разработчиком могут вноситься изменения только на девелоперских серверах и только при условии, что разработчик понимает, что делает. Эти файлы ресурсов никогда не коммитятся в репозиторий SVN и любые изменения в них должны быть согласованы с администратором системы.
Логи
Логирование работы приложения — важная часть работы программиста. Грамотное логирование позволяет быстро и эффективно находить ошибки в коде, оценивать скорость выполнения функций, собирать диагностическую и статическую информацию о пользователях системы и пр.
Использование сторонних библиотек для логирования не всегда бывает целесообразным, т.к. зачастую это может существенно замедлять работу приложения.
Общим правилам логирования посвящен раздел [logs]. В этом разделе будет идти речь только о логах, которые выводит библиотека lib_meta.
Уровень логгирования loglevel
loglevelЛоги могут быть менее или более подробными, от вывода только критических ошибок (например, эксепшнов) до вывода отладочной информации. За уровень логирования приложения отвечает параметр loglevel основного файла ресурсов (см. ResourceBundle):
-
loglevel=0 — вывод только критических ошибок -
loglevel=1 — вывод сообщений об исполнении функций (вида M:E M:Ob M:A M:D M:S) и некоторых, самых важных, подробностей -
loglevel=2 — дополнительно кloglevel=1 подробный вывод внутри функций -
loglevel=3 — дополнительно кloglevel=2 вывод некоторых ошибок боле развернуто
Уровень логгирования, указанный в mains, можно и нужно учитывать при написании кода всего приложения. Также нужно не забывать о том, что каждый вывод в лог замедляет работу приложения в целом, особенно при росте нагрузки на боевых серверах.
Вспомогательные механизмы. События
1. Определение
Событие — это сообщение, которое возникает в различных точках исполняемого кода (как правило, при взаимодействии пользователя с системой), при выполнении определенных условий. Эти сообщения направляются обработчикам событий ("слушателям"), что позволяет своевременно реагировать на изменившееся состояние системы.
Пример. Пользователь редактирует время вылета рейса. В соответствии с внесенными изменениями необходимо проделать целый список операций:
-
найти все заявки туристов, вылетающих данным рейсом в даты, на которые пользователь скорректировал расписание, изменить время вылета рейса в них;
-
перегенерировать пакет документов в каждой заявке и разослать туристам письмо-уведомление об изменении времени вылета их рейса;
-
проверить наличие у принимающей компании уже сформированных транспортых групп (автобусов) для встречи туристов, и если группы созданы, то скорректировать время подачи автобуса к рейсу, а также разослать письмо-уведомление водителям и трансферменам об изменившемся времени прибытия рейса;
-
и т.д.
Все вышеперечисленные операции должны выполняться для пользователя неявно, то есть автоматически: пользователь просто редактирует расписание рейса, а остальное делает система.
Разработчик не должен заставлять пользователя ждать, нажав на кнопку, пока система выполнит ряд действий для обеспечения целостности всех ее частей. Вместо этого разработчик инициирует ("испускает") событие в момент нажатия пользователем кнопки "Сохранить изменения", просто уведомляя систему о том, что у рейса с ID=[1031…] изменено расписание на период с 01.08.2020 по 31.08.2020.
2. Типы событий
Чем больше система, тем больше действий пользователей требуют проектирования новых типов событий. Для того, чтобы отличать один тип события от другого, за каждым событием закрепляется номер.
public static final int E5 = 5; // изменена квота на рейс
public static final int E6 = 6; // изменено расписание рейса
3. Очередь событий
В момент инициации событие попадает в очередь на обработку. Для хранения очередей событий используется redis.
У каждого типа события своя очередь на обработку.
События из очереди обрабатываются в порядке FIFO, если не указано иное (см. Отложенные события).
После обработки событие удаляется из очереди.
4. Класс EventListener
Класс, содержащий перечень типов событий, а также методы для обработки каждого типа события, называется EventListener.
В каждом проекте есть свой EventListener, который является расширением абстрактного класса util.EventListenerBase библиотеки util.jar или расширением класса shop.EventListener бибилиотеки shop.jar.
Класс EventListener проекта обязательно переопределяет в себе метод processEvent, который должен содержать в себе обработку каждого используемого типа события:
public void processEvent(Obb event, ResourceBundle mains, String path)
Под каждый тип события разработчик пишет метод его обработки и включает его в processEvent.
5. Инициация события
Для того, чтобы инициировать событие из точки кода, необходимо вызвать метод fireDelayedEvent2Chain класса EventListener, если метод был переопределен, или класса shop.EventListener, и передать ему набор параметров, например:
new shop.EventListener().fireDelayedEvent2Chain(ResourceBundle mains, int eventType, String strvObjId, String strvComment, String dateTime, int chain);
Где,
- eventType — номер (тип) испускаемого события
- strvObjId, strvComment — смысловая нагрузка данного типа события
- dateTime — дата и время начала обработки события в формате ДД.ММ.ГГГГ ЧЧ:ММ:СС (обработать не ранее, чем в), по-умолчанию Util.getDate1() (=текущая дата и время), см. Отложенные события
- chain - номер цепочки, по-умолчанию -1, см. Цепочки
Пример.
new shop.EventListener().fireDelayedEvent2Chain(mains, EventListener.E5, q.fDate, q.idOb + "^" + q.className, Util.getDate1(), -1);
Где,
- q.fDate — дата вылета рейса в формате ДД.ММ.ГГГГ
- q.idOb + "^" + q.className — идентификатор рейса и класс перелета, например 103199999999^Y
6. Отложенные события
Иногда бизнес-задача требует обработать событие не сразу после иницииации, а не ранее, чем через какое-то время — минуты, часы, дни. Такие события называются отложенными.
Для того, чтобы инициировать отложенное событие, достаточно передать в метод fireDelayedEvent2Chain в параметр dateTime минимальное время, не ранее которого можно взять событие из очереди на обработку.
7. Обработка события и обработчик события
Метод для обработки события определенного типа вписывается в функцию EventListener.processEvent в конструкцию switch-case.
Обработчиком события любого типа является запускаемая java-программа (класс Robot), которая "забирает" из очереди накопившиеся события, к каждому событию применяет прописанный этому типу метод обработки, а после обработки события удаляет его из очереди событий.
Пример запуска обработчика события из консоли.
$ /usr/java/latest/bin/java -cp /w2/srv/.../WEB-INF/classes:/w2/srv/.../lib/*:/w2/srv/.../lib:/w2/srv/.../WEB-INF/lib/* [package].Robot [project]_main 0 eventredis [номер_события]
8. Просмотр очереди событий через web-интерфейс
Просмотр очереди событий полезен для отладки, когда разработчику и тестировщику необходимо убедиться в том, что события инициируются правильно.
Для любого проекта можно настроить просмотр очереди события через web, например:
http(s)://.../util?action=preview&task=ListOfEvents&ptype=[номер_события]В данном случае /util — это сервлет shop.UtilsServlet, то есть библиотека shop.jar подключена к проекту, но могут быть проекты и без shop.jar, тогда настройка отображения очереди событий, при необходимости, может быть настроена вручную в любом другом сервлете проекта.
9. Оформление в системе задач
Если в закрываемой задаче редактируется обработчик какого-либо события, то в URL’ах на выкладку необходимо указать номер события c указанием имени проекта через ":", например: sh:E512.
Термины, определения и сокращения
- БДБаза данных;
- БГТуроператор "Библио Глобус";
- РоботJava-программа, исполняемая на сервере;
- СервлетИнтерфейс Java, расширяет функциональные возможности сервера и взаимодейтвует с клиентом посредством HTTP.
Понятия системы МЕТА:
- Блокхранилище данных
- Типсущность предметной области, объект системы МЕТА
- Атрибутхарактеристика сущности(-ей) предметной области, объект системы МЕТА
- Объектконкретный экземпляр типа, имеющий уникальный идентификатор
- IDуникальный идентификатор
- Цепочкахарактеристика объекта
- Хостсервер
- ПлейсМЕТАданные о хранилищах системы МЕТА, объект системы МЕТА